

Why enterprises aren't ready for AI Agents yet
The tension between the need to deploy, the complexity and the need for flexibility

Welcome back to Reasoned by Nikhil Pahwa, a guide to how AI is changing the world around us.
I know I’ve been a bit scarce of late, but there was a lot of work at MediaNama, and I’ve run two successful vibe coding workshops, apart from a long trip to Singapore for SuperAI and a little bit of a break in between meetings.
The third Vibe Coding workshop in Delhi is on July 4th, and I’m rolling out corporate AI workshops shortly.
I have three corporate workshops planned: Introduction to AI (for those still finding their feed with AI), a Vibe Coding with AI workshop (to get a sense of AI capabilities beyond just chat, and actually learn how to deploy on the web), and lastly, How AI is changing the world, an AI strategy workshop based on this newsletter and how AI actually works.
Today’s newsletter is about AI and enterprises, based on three talks at SuperAI, distilling their learning.
Why aren’t we seeing mass deployment of agents in enterprises, across functions?
A manufacturing company founder I know has a simple thesis for deploying agents in his company: when you need information, analysis or research, people in the loop can often become constraints: in an organisations that has thousands of employees and customers across jurisdictions, it can take time to pull out data, prepare reports, and deliver information to act upon.
Interoperability allows an agent to pull information from various sources, whether the ERP, inventory management systems, management information systems, sales, HR and finance, and give reviews and recommendations, create dashboards, and help speed up decision making for business owners. Nobody cares about which model is being used or which harness: they just have jobs to be done.
I’ve noticed that while founders are at present empowered to deploy agents for themselves: organisations themselves have lower risk-taking capacity.
Still, enterprise adoption of AI agents remains slow, and three talks at SuperAI, from Snowflake, Alibaba Cloud and Sierra highlighted some challenges and offered some solutions:
1. It’s all about the harness: Harshil Mathur, CEO of Razorpay said on x recently that businesses will either be the model or the harness. AI models have crossed a capability threshold for reasoning, tool calling, and large context, but the harness is where the complexity lies.
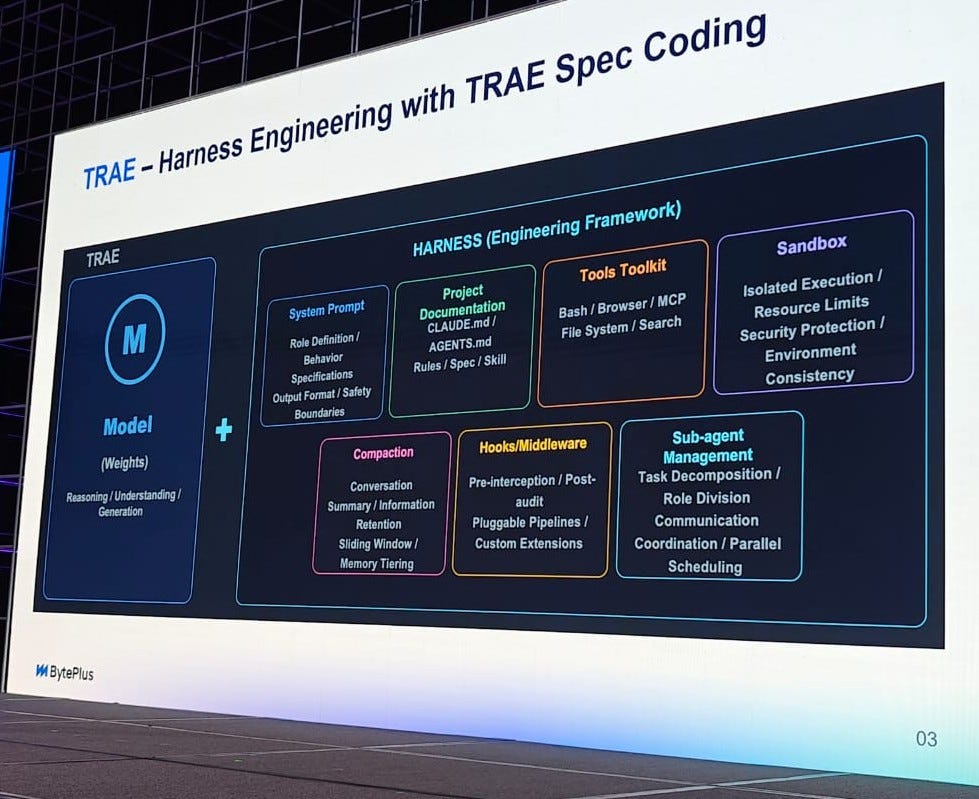
The harness is everything around the model that controls its behaviour, and while definitions of harness vary, it includes everything from what an Agents’ soul.md contains, the tenets it has, the skills it uses creates and improves, how it responds to user requests, what tools it invokes, how it connects. It’s why, for the same model, Claude Code works differently from Opencode: the constraints vary.
When Alibaba Cloud’s Ken Xu sits down with enterprise customers, the conversation is never about the model, he said at SuperAI:
“The bottleneck is no longer can the model do it or not. The bottleneck is can the enterprise put it into production safely. That’s an architecture and harness problem, not the model problem anymore.”
“When you build your own agent, you’re not just calling the large language model. You are building a runtime that execute multiple task plans, a memory system that survive across sessions. A tool layer that touches your production data, governance for compliance, and observability to debug what the agents actually did.”
He framed it as “agents as a system, not a feature”, and frankly the challenge lies in the production stack, the organisational readiness, how agents deal with customers speaking in three languages in a single sentence, how they handle payment issues, or dropped calls and resumed conversations. It’s complicated at scale, and the system has to keep evolving as more behaviour is leaned. That level of complexity can scare organisations, and that’s where it gets stuck.
2. Five problems that keep surfacing: Xu highlighted five problems that keep surfacing:
1. Fragmented tooling especially when different teams use pick different agent frameworks. I think this expands to different teams using different tools for their work as well.
2. Brittle integrations: integrations vary across teams and companies, and each integration is brittle in its own way. Interoperability is a struggle, and users who use personal agents know about how Whatsapp keeps getting signed out every 14 days, and if your Google Cloud setup is in trial mode, you have to authenticate access every seven days. Integrations and interoperability across tooling means more can go wrong as you integrate more tools
3. Governance gap: “No share policy, no audit trail, very little bit of guardrails”. Compliance teams have no visibility into what agents are doing or have done. On observability, Xu was insistent that the production stack needs “every step replayable, scorable, and it can feed back into your next development cycle of your agent.”

4. Runtime fragility: “Long-running agents need sandboxing, retries, and checkpointing. Most stacks actually don’t have this.”
5. The talent gap: “The experience. Very few teams have shipped agents to production before.”
These five problems compound each other, and most enterprises haven’t even encountered them yet because they’re still at the experimentation stage.
3. Most enterprises are still doing AI tourism: AI has a tourism problem, a friend had highlighted early last year at a closed door discussion that SaaSBoomi (now AIBoomi), had held. For his AI service, it was about a flood of users signing up, trying something out with free tokens and never returning.
Sierra’s Damien Tampling said that AI tourism is becoming a little like a hop-on-hop-off bus: “you hop on the bus, but you never necessarily hop off. It’s a completely different experience. You’re not really getting into the nitty-gritty or the back alleyways of the city. You’re not really understanding what it’s like to live there. It’s almost like window shopping.”
People aren’t taking the next step towards buying, he said, and alignment is hard: organizations need alignment across divisions, which is hard and takes time, and the complexity underneath reinforces the hesitation. For example, how do organisations deal with an AI lying that a task is done when it isn’t?
4. The complexity scares companies: Tampling showed a demo of voice simulations where production calls came through with background noise, people saying one thing and changing their mind, different languages, different accents. Both sides of the simulated call were actually agents, one simulating a human caller complete with hesitation, background noise, and mid-sentence corrections.
“You’d think that, well, we’ve got LLMs, we’ve got RAG, we’ve got some tools, let’s go and build AI. But it’s this stuff that’s causing the problem. It’s this stuff that needs to be navigated through, and it’s significant.”
The customer support agent, over voice, has to handle PII detection, payment processing within agent conversations so customers aren’t pushed off to another call, multi-step Q&A flows, language and cultural nuances, voice models that don’t work in certain countries. Each sub-problem is individually tractable, but together they create a combinatorial challenge most teams underestimate. He called the complexity an Agent Iceberg (not the only one in the conference to use an iceberg as a metaphor):

5. Voice is very challenging: Some founders I have spoken to don’t want to type: voice interaction with an agent is a preferred approach. Voice models also fail at consistency, not capability. Sierra built a benchmark called TAO Bench to measure something most AI benchmarks ignore: whether a model can do the same thing reliably across multiple instances.
“What we found is that when N was one, one instance of it running through, it maybe got to 40% or so. But once you got to eight instances of that same interaction happening, most of the voice models were failing. They weren’t actually consistently performing.”
Additionally, Asia-Pacific is where the voice consistency problem hits hardest. With 60% of the world’s population and 45% of its languages, the region forces a level of sociolinguistic complexity that most agent architectures aren’t built for. Tampling gave a specific example with Mandarin:
“One word can mean something completely different if you’re talking to a 65-year-old male in Beijing than it might mean for a young Singaporean who’s bilingual, speaks English and Mandarin or Chinese.”
A deployment in the Philippines surfaced an even more granular challenge. Filipinos switch between Tagalog and English constantly, in a mix called Taglish, but the ratio varies wildly from person to person:
“People call up our agent and they’ll interact and flip between Tagalog and English, Taglish, but some people will do it where they’ll insert an English word every five words, and some people will do it insert an English word every 15 words. And our agent actually needs to read this situation and then adjust and mirror the way that they’re actually talking back.”
Getting this wrong is an instant fail, and those fails cause enterprise clients to pull back from deployment entirely. “There’s no way you can be deploying agents for large banks or airlines or others if you’re not starting to master this,” Tampling said. Solving it “requires you to actually lean in almost beyond your product and actually work on actually getting the right language models to make it all come together.” This requires ground-up language work, and most enterprises operating in this region haven’t started thinking about it.
Deployment advice
Some inputs from the session on how to deploy agents in the organisation:
1. Design for how agents fail: Sierra’s team works through failure scenarios with clients, and the kind of questions that only surface once you’re in production:
“What if this happens, what happens if the call drops out? Does it pick it up from where it finished? Do we go through re-authentication?”
Production agents spend most of their time on the path where the user interrupts, the connection drops, the input is garbled, or the system times out. I’ve written about how agents are designed to route around barriers, and that applies here: agents need to be designed to route around their own failures gracefully. The enterprises that design for failure modes are the ones whose pilots survive.
The gap in the market that Tampling identified is is post-launch diagnostics: everyone focuses on building agents, and getting to production, but post that, the focus has to shift to diagnosis, fixing and continuous optimisation. As anyone deploying agents will tell you: deployment is the easy part. You can’t design for every failure up-front, and fixing something that gives probabilistic outcomes is a continuous exercise.
2. Full autonomy is the wrong goal: Tampling said that the idea of end-to-end agent autonomy is premature, and there should be instances in the workflow where the agent hands off to a human.
Xu concurred, saying that it’s important that enterprises should “pilot with human-in-the-loop, scale the autonomy and confidence and growth.” The challenge, as I’ve written previously, is that after the agent has acted correctly a few times, we tend to stop supervising it closely. Autonomy has to grow as the system proves reliability, which means handoffs are essential to its architecture.
3. The Build vs Buy question:
Xu highlighted that Alibaba Cloud, which itself runs enterprise agents, decides on build vs buy in the following manner, saying that the two decisions are complementary: “Buy what gives you speed, build what gives you the competitive edge.”
The “buy” side covers categories where custom agents aren’t worth the effort: coding assistants, customer service, research, sourcing. Alibaba showed an e-commerce agent team with five sub-agents handling storefront management, market research, competitor monitoring, sourcing and negotiation, and social media. Xu called it “the one-person company idea made real. One person, one agent team, a global storefront live in just 15 minutes.”
On the build side, Voyager, a cross-border travel agent built by a customer on Alibaba’s agent services, uses a multi-agent architecture: one intent recognition agent at the top and scenario agents below for itinerary, hotel, transport, and tour guide. However, they did not build the runtime, memory, tool layer, or governance from scratch.
4. Context needs to learn on its own
Snowflake’s Soo Lee made the standard case that “there’s no AI strategy without a data strategy.” What’s newer is what Snowflake built on top of that foundation. Cortex Sense, which she demoed, automatically gathers metadata and business context from ongoing user activity:
“Instead of manually teaching AI how to map business, the context layer becomes smarter over time on its own.”
In the demo, an agent connected fan engagement data from one dataset with merchandise data buried in dashboards, without being told how the business logic connects them. Lee: “I didn’t have to tell how the business logic works or logic parts. It just figured it out by looking through my past behavior.” This is where the interoperability question meets the context question: the more surfaces the agent can access, the richer the context. That being said, as I’ve written previously, models struggle to decide what to use, retain and discard from context at scale, and memory introduces the question of how the system forgets, reinterprets, and prioritises over time. The more you use agents, the more that issue compounds.
5. Avoid model lock-in: Sierra avoids betting on a single provider entirely:
“Having more of a constellation of models approach where you can move between the different models, whichever one is the best for a particular interaction. And based on their strengths and weaknesses, and sometimes latency and sometimes upgrades and sometimes many other things, having that flexibility we think is a real advantage in this world that we’re moving into.”
Snowflake’s Lee made the same point from the platform side: “Our customers don’t want to be locked into a single model provider.” Snowflake now offers Gemini, GPT, Claude, its own Arctic model, and SpaceX’s Grok, with new models available same-day (Claude 5 was announced during the conference and was immediately available within Snowflake). Enterprise agent infrastructure should be model-agnostic.
What none of them spoke about
The part that none of them spoke about,obviously, was actually making the agentic deployment harness-provider agnostic: as I wrote about in the context of Meta’s Manus acquisition, enterprises are locking in vendor relationships that will be nearly impossible to unwind. While models are fungible, how do you make the harness fungible and not vendor dependent. Some you own: the skills, and the outcome of self-learning, but the dependence is based on the MCPs you integrate, the memory store you lease, and many of the services that the companies these speakers work for themselves provide.
Every business tries to lock customers in, an a rapidly evolving AI environment, you want to be able to move to the next set of tooling. This isn’t just a money issue: even with open source tools, what breaks in terms of what my agent does or behaves when I move from an Hermes agent to an OpenClaw setup, or an SQlite database to a Honcho database, or an n8n integration to an Activepieces integration?
If you look beyond the complexity of deploying and maintaining the deployment, there is a clear tension between the need to deploy now, and the risk not being flexible in a rapidly evolving space.