

An AI product turned me into a feature
And it feels like theft

So the craziest thing happened a couple of days ago: Someone in my team was using Grammarly for an article they were writing, and it recommended me (Nikhil Pahwa) as an expert advisor for their article. It lists me by name, mentions that I’m the “Founder of MediaNama and leading Indian digital policy journalist”. This is a premium paid service.

For the user, this is just another premium feature, and I’m just another name on it. For the platform, it is probably a monetization mechanism, and they’ve probably picked experts whose “inspired” advice a user might pay for.
It’s just that I never signed up for this. I’ve never — as far as I can remember — ever used Grammarly. I certainly haven’t given them consent for using my name, and yet, here they are — using me as an advisor to someone without my permission.
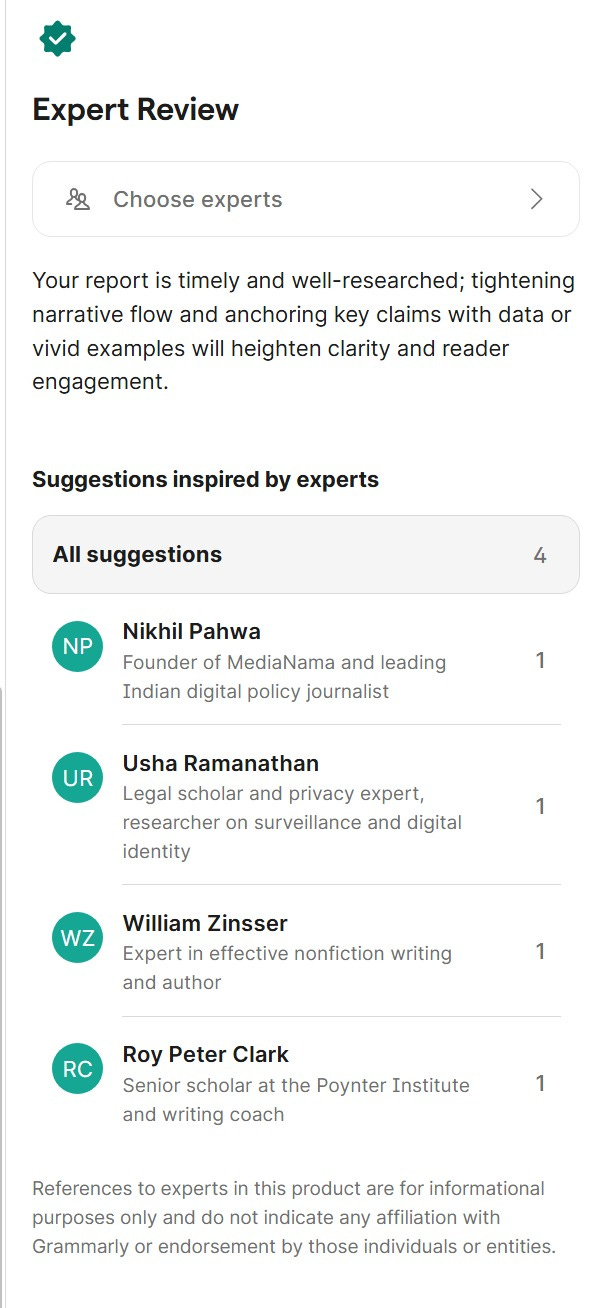
I feel appropriated: this is not just about advice on text. It’s about leveraging my credibility, something I’ve built consistently over two decades of work, and that is exactly makes this unauthorised use feel like a violation of my rights.
They have something of a disclaimer on top, saying this is “inspired by experts”. Another at the bottom says “references to experts in this product are for informational purposes only and do not indicate any affiliation with Grammarly or endorsement by those individuals or entities”.
This suggests that Grammarly has probably taken my writing, parsed how I write, what I say, what advice I might give, and used it to infer what I might advise someone. Meanwhile, the interface still conveys derived authority strongly enough to sell the feature as a paid service, such that an endorsement or a licensing relationship may be assumed, so that has to be disclaimed.
This is legal weaseling: specific enough to appropriate credibility to sell a service, but still disclaim that appropriation to avoid accountability.
To use the same approach: I’d say this “feels like” theft.
Reasoned is where I write about how AI is changing the world, whether its Commerce, Social Media, Content, Classifieds, Payments or even war. I publish twice a week.
Do consider subscribing.
I will write on AI and Education, Digital Payments, Music and AI Operating systems.
To get a sense of what I’m writing about and what’s next, start here. .
I thought I was prepared for this
When I first started using AI meaningfully, early in 2023, it was as an experiment to see whether AI could replace me. Using my own writing, I reverse engineered my writing style, tone, voice, structure, length of output, among other things. It’s what I taught around 128 journalists about prompting in 2024. Over the last few years, I’ve tried to replicate not just my writing style but my thinking, formats, and tasks. I have about 87 custom bots on ChatGPT, split by function first, but all with my personal approach to doing things. Content and tasks were always fungible, and I learned that from ChatGPT.
None of this, in other words, was unimaginable to me.
From Claude, I learned that skills are fungible: I now have 49 skills on Claude, some of which, are skills I do not possess, but would like to have. Someone recently published a skill on Github for scripting reels in the style of Varun Mayya. AI is no longer just about generating outputs: it is now replicating the skills required to produce these outputs.
For builders this is an opportunity. For professionals, this is a threat: It is possible to replace some of what I do by reverse engineering my skills based on what I have done.
Anyone like me, who writes regularly, publishes analysis, or gives public advice, as I have done for 20 years over thousands of articles and social media updates, is effectively leaving behind a map of how they think.
My public portfolio is someone’s training dataset.
Why this feels like appropriation
We ran an exercise last Saturday on MediaNama, of identifying what kind of work cannot be replaced by AI when everything appears replicable.
What is not fungible is the new information, the new analysis, the new patterns, and the new gaps that we can identify based on what we can see. I’ve always taken things from the past and projected them to the future, and taken concepts from one sector, like payments, and applied them to another, like the music industry. We remain useful by bringing ourselves to the writing.
Now Grammarly is effectively saying that it’s making some cheap knockoff of my advice available to users. This was the first moment that I realised that my public work and expertise has been silently been operationalised as a feature in a product.
When I look at Grammarly claiming that that advisor is like me, I feel copy-able, fungible and hence substitutable. I feel like I’ve been stolen.
What is the difference between a deep fake and an almost deep fake?
You do not need to replicate a person completely to substitute parts of their work: just about useful enough to make money off their derived expertise and authority.
What can I do here? What rights do I have here? Can I prevent Grammarly from using my name without my consent? The law focuses on copyright, impersonation and deepfakes. Can expertise be protected by law, since anyone with a public body of work may now be reconstruct-able?
Do I have to go to court and protect my “Personality Rights”? Celebrities, and don’t you dare call me a celebrity, have gone to court to protect their likeness, their voice-likeness, and even phrases that they are associated with. Their identity has commercial value, and it appears that now, so does mine.
What’s worrying here is that most people — users, writers, researchers, analysts, creators and professionals — do not have the resources or awareness to defend these rights. I have the connections to get the attention of someone at Grammarly, but what if they refuse to do anything?
So far, there’s no response to my questions sent to Shishir Mehrotra, the CEO of Superhuman.
What this means
A friend asked me for advice related to a product he is considering, which focuses on using AI to determine fitment. My suggestion was that because with incomplete data AI will make assumptions to fill in gaps and hence make mistakes, the focus should not be about determining how right something is, but how to be less wrong, to borrow a concept from Charlie Munger, with the information we have at our disposal.
Given how much information is available about me in the public domain, if that is coupled with my notes, emails and access to all my private surfaces, even voice notes (which much of this article is drawn from), there is a possibility that AI’s understanding of me would be so comprehensive that I’m replaceable: my clones will become more like me. Outputs will be less wrong.
It’s why we feel that platforms are becoming more useful: they’re training on their conversations with us.
In effect, they’re trying to be less wrong when it comes to doing what I tried to do with ChatGPT: replace us.
*
Related:
This was an issue that was highlighted on the the NY Times Hardfork podcast, apparently Grammarly have since apologised and withdrawn the feature with immediate effect.
https://www.platformer.news/grammarly-expert-review-reviewed/
Would you be looking to take legal action against them?