

AI is replacing human creativity. Who pays for the original?
How scale, substitution, and AI training are reshaping the economics and incentives of human creativity.

I have stories on AI and copyright to tell.
First story: for a year, starting early 2023, five months after ChatGPT launched, my favorite thing to quiz people on at parties and gatherings was ‘who owns a dead persons voice? I was essentially asking if a music label can sell someones voice samples to an AI model to replicate them, after they’ve died?
Second story: A few months later, when the global rep of an huge AI company spoke at a closed door meeting, I asked about whether a robots.txt exception applies to AI training, like it does on scraping. That person didn’t understand what I was talking about. For the uninitiated, you can instruct Google to not scrape your website data by creating an exclusion in robots.txt. At that time both OpenAI and Google (Bard) were live, but neither respected robots.txt exclusion. Last week someone from a big-tech industry claimed that their company respects copyright because it follows robots.txt exclusions. They changed the subject when I pointed out that scraping for AI training preceded robots.txt exclusions.
(Reminder: You can’t claim to respect the rules when you only start following them after you’ve knowingly broken them.)
Third story: Last year, I asked the head (not owner) of the digital arm of a large media company, who I’ve known for well over a decade about why they aren’t doing anything about enforcing copyright for news scraping. His response: “Sir, I am just looking for a deal here. If I can make my quarterly revenue targets, I’m good. Anyway, it’s not my content.”
Fourth story: Last year, I got into a heated argument with a former civil society exec (now consultant) about his claim that if you can’t prevent someone from reading your website, you shouldn’t be able to block an AI crawler because AI is merely reading your content and learning from it.
Fifth story: At a meeting on AI earlier this year, when I raised a question about how law must evolve to protect copyright owners and creators, a computer scientist in the room stood up and said - You have no right to copyright when the cost of content creation tends towards zero. Copyright needs to end.
That last one really hit me.
On how India is proposing to address the issue of AI and Copyright
Where are we and why: ANI sued OpenAI in the Delhi High Court, and since ministries can’t be seen as doing nothing when there’s a key policy issue at stake, DPIIT constituted a committee of three government stakeholders, two lawyers and two representatives from NASSCOM, a lobby group representing tech and IT companies, to resolve the issue. The committee released its report, with NASSCOM dissenting because they want a free-for-all for clients (AI companies) while the committee decided to bring “balance” by proposing that AI companies be allowed to take data without permission (via a compulsory license to copyrighted content) and deposit a percentage of their revenue with a copyright society to distribute as pittance to companies that own copyright. This is paper open for responses till January 8th 2026, and lobbyists and lawyers (who also also often lobby for their clients) will be writing opeds and LinkedIn updates that serve their clients without adequate disclosures.
You can read the report here.
Before we get into the weeds of Copyright and AI, it’s important to understand how Generative AI models work
Generative AI models like ChatGPT are typically next-word-prediction models: they’re trained to predict the next word (or more precisely, the next token, which may have a series of words) in a sequence based on the context of previous tokens. How it is able to do this is somewhat beautiful. They scrape truckloads of data from the Internet and from website content, books, articles, social media posts etc from copyright owners (in case of Meta, it appears they’ve also taken content from piracy websites like Libgen) to predict in a probabilistic manner, which word should come after the next. They determine statistical connections between words.
Andrej Karpathy calls the development of AI models lossy compression: the model develops a compressed internal representation of language, concepts, and patterns, and it’s “lossy” because it does not retain the full detail or exact structure of the input, but just what it needs to predict the next token effectively. The billions of parameters in the model are effectively a compressed summary of statistical patterns across trillions of tokens from the training set.
When you ask a chatbot a query, it tries to understand what you’re asking, and in a probabilistic manner, based on patterns learned across all the data that it has collected (and compressed), it tries to give you the best possible response to your query or prompt. This response is not based on facts but largely determined by weights given to text during training, its understanding of your query, and the past history of its interactions with you. This is why Generative AI often makes up information because its job is to give you an answer, not to be factually correct. If you give a chatbot a different role (accountant, copywriter), or constrain it via prompts (avoid rosy language, be blunt, ignore certain aspects etc), its answers change, and it moves to a different pattern because of your directions. In the end its only goal is to give you what you want based on the probability that you’ll be happy with an output. Responses are not verified for factual accuracy, they are generated based on statistical patterns learned during training, which may include factual information, but without the model knowing what is true or false.
What you need to understand here is that there are two separate stages where copyright violation is considered: first is when data is collected, and second is when there’s an output.
I’m going to address arguments made by AI companies one by one.

First: It’s not substituting. It’s transformative use
AI companies argue that when Generative AI tools create an output, it isn’t replicating word-for-word, note by note, or pixel by pixel, the work of an original creator. They merely use the text collected to determine patterns and give an output, but not replicate the output. The output might be similar but it isn’t same, so it isn’t copyright violation.
This is clearest when it comes to text: I could feed in the entire Harry Potter series and probably a rewritten copy of each book - structurally the same even if the text is different.
Just because it’s not word-for-word doesn’t mean that it’s not theft.
Copyright is meant to protect original expression, not just how one word follows the next. Secondly, the fact that training material used copyrighted data itself should be seen as a copyright violation, so it’s not just about the output.
The model may produce outputs so stylistically close to the original that they functionally as substitutes. This is especially evident in music, where streaming services and YouTube are full of AI impersonation.
A YouTube video of AI generated Frank Sinatra singing Nirvana’s Come As You Are, which I’ve heard, violates the rights of both. It’s pitched as homage, but it’s just identity theft and copyright violation.
In the same vein, I could use AI Agents and a simple rephrasing prompt fill a website with inexact replicas of each article that the Times of India publishes: that is substitution.
Before you read further, do consider supporting my work
by making a payment here (if you’re in India) and here (if you’re not in India).
Perplexity and Google’s AI summaries collect factual information from across websites, collate them and present them to users: it is transformative usage, and takes a Wikipedia approach to news, but it is substitutive.
The DPIIT Committee Report correctly recognises this problem and points out: “This substitution effect threatens creators’ earnings and, consequently, their future investment capacity.”
Impact on the market for copyrighted work
It also highlights that, “according to data from the Harvard Business Review, the launch of ChatGPT led to a 30% decline in writing jobs and a 20% reduction in coding roles.
Also, AI image generators resulted in a 17% drop in image creation jobs. This is cited as evidence to say that it is ‘self-evident’ that generative AI will compete with its training data.”
Beyond job losses there is a major impact on the market for copyrighted work, because of how flooding of marketplaces with AI content impacts discovery and monetization:
In case of Books: AI Generated books are flooding Amazon, probably assisted by tools like this one that can, it seems, generate 20 chapters of 30,000 words easily.
In case of Music: Spotify is full of AI music that is being recommended to users, and it’s full of AI generated content that includes impersonation, but it still has AI generated artists. 20% of the songs uploaded to Deezer on a daily basis are AI-generated, totaling nearly 30,000 tracks a day.
In case of News, there’s real data: As Google shifts from AI Overviews, which already impacted traffic, to AI Mode, which will kill traffic for external publishers, the future of news looks bleak. Two excerpts from this Guardian article:
“A new analysis by the Authoritas analytics company has found that a site previously ranked first in a search result could lose about 79% of its traffic for that query if results were delivered below an AI overview.”
“A second study also showed a big hit to referral traffic from Google AI Overviews. A month-long survey of almost 69,000 Google searches, run by the Pew Research Center, a US thinktank, found users only clicked a link under an AI summary once every 100 times.”
Google was also found to be self-prioritising YouTube over other sources, but that’s more of a competition concern, not a copyright one.
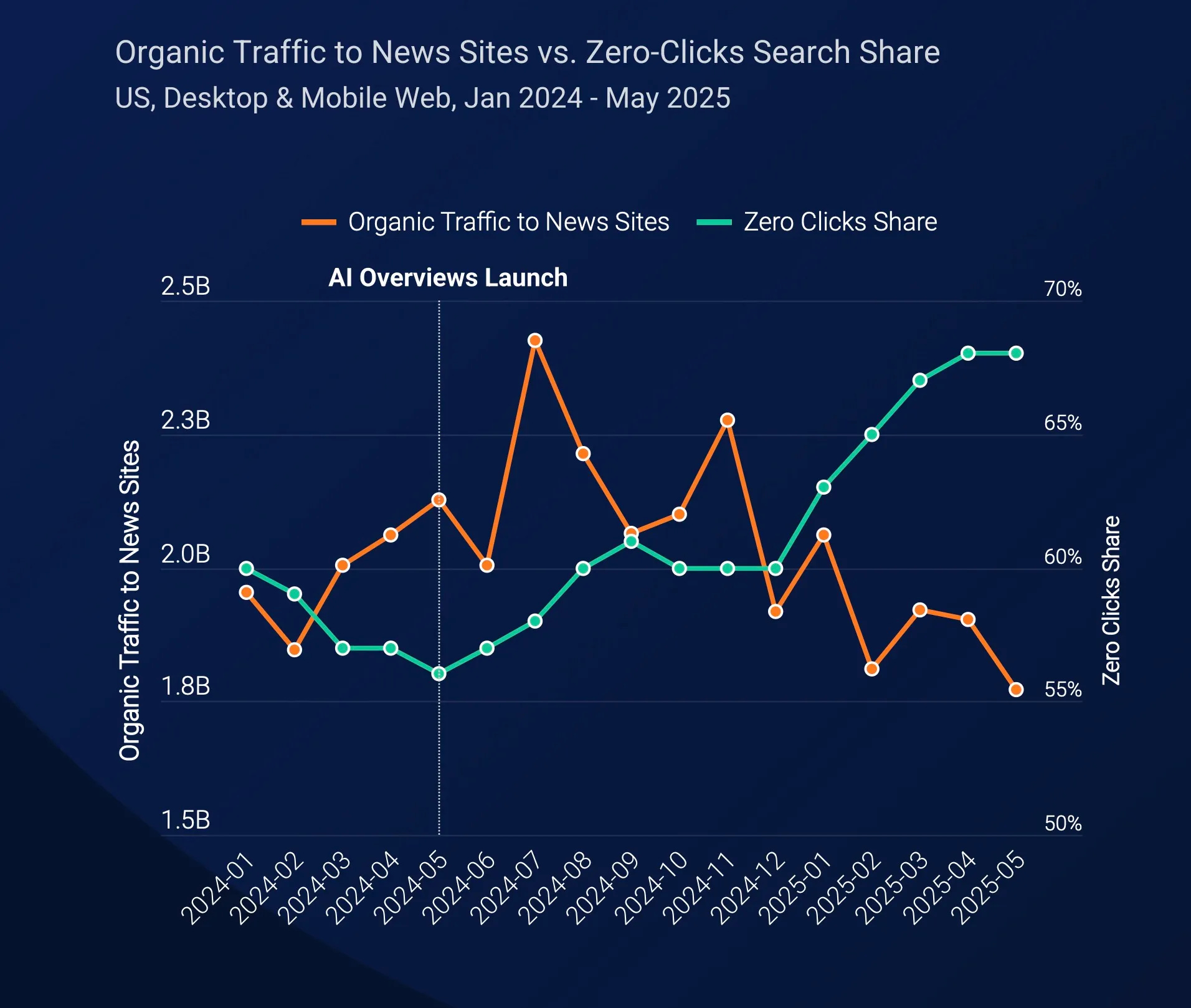
Apart from this, there’s some data from SimilarWeb that is very scary about the impact on AI overviews, even as ChatGPT referrals to news sites are improving.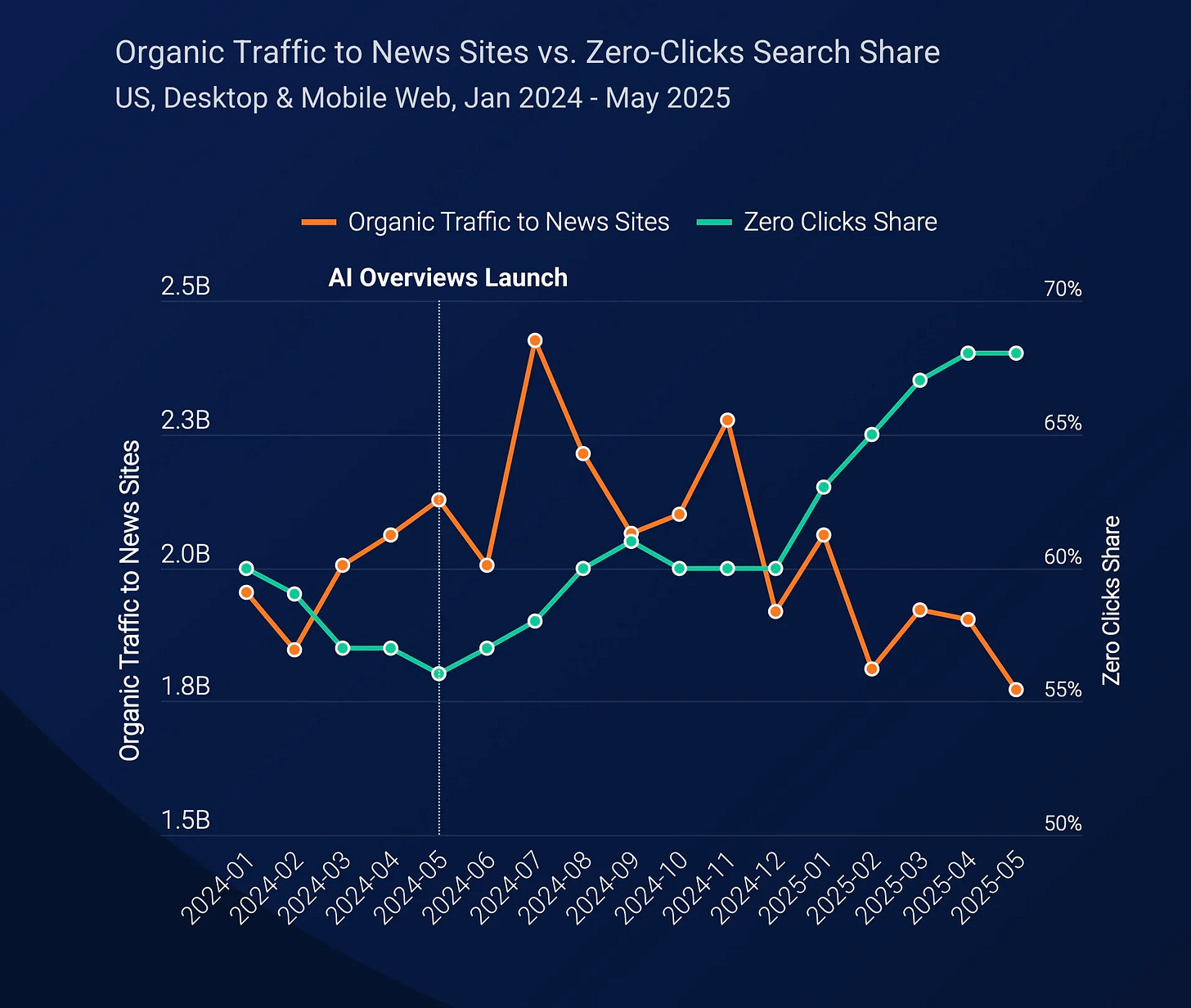
Source: SimilarWeb via Techcrunch
While rewriting might be treated as Plagiarism, and one can argue that facts aren’t protected by Copyright, I can explained why this is problematic last year:
They’re cannibalistic: “…such tools are extractive and cannibalistic, rather than value additive for publishers. They end up reducing the need for someone to visit the source of that information, effectively stealing their audience and means of monetization via advertising and subscription.”
“Perplexity and AI summaries […] address the users’ needs directly, thus alleviating the desire to go to the source. The user and the ‘answer’ engines win, but the publisher loses. This means that publishers cannot monetize the users presence via subscription or advertising, or encourage repeat usage via newsletters and apps.”
In this game, AI gets smarter, users get answers, but the publisher and the source of content gets nothing.
AI tools cannot be treated the same as human copiers because a ‘Power Law” should apply: “the mass accumulation of content for training without permission or compensation cannot be treated the same way as human learning: there is a power law applicable here, and with ability to ingest, learn and replicate (even if not verbatim) at scale: the impact is disproportionate and exponential.”
That last point is critical. Human being can read something and explain it in her own words. No human being has the ability to do this across millions of pieces of content. In the same vein, a human being can mimic a famous actor: there are enough performers who dress up like Elvis Pressly, and mimics who can speak like Amitabh Bachchan, but AI tools can substitute them and everyone else at scale.
AI doesn’t just mimic one creator - it mimics all of us, all at once, and sells it for everyone to use, at scale. Imitation at scale is industrialisation of plagiarism. It’s not innvoation.
I’ll end this now with few points, and I’ll write a second part tomorrow addressing other arguments:
First, as a creator and a copyright owner, my work is being used to train the machine that is replacing me.
AI will mimic the skillsets of creators and give it to those who haven’t spent the time, effort and money in acquiring those skills. Shouldn’t I have a say in this? Shouldn’t I be able to prevent this?
Second, what will become of the incentive structure for human creation? I’ll go back to story number 5 above: If the cost of creation is tending towards zero because of AI, it is because it is built on countless hours of work in creation of copyrighted and non-copyrighted content from human beings. Our work is being used to substitute us, and rob us of the benefit from our own creation. Shouldn’t some benefit accrue to me if my work is being used to benefit someone else?
That’s not just a moral question: it’s a legal and economic one. If consent is optional and compensation is trivial, copyright becomes meaningless.
Third: We have to take into account what AI is doing into the entire digital economy. I wrote earlier about the extractive nature of AI, and it’s important to remember: AI isn’t just learning from the internet to help us. It’s learning from the Internet in order to replace it.
Read: AI and the quiet rewiring of the Internet.
Fourth, this means that the incentive structure for human creation will collapse because of AI, maybe not for all, but for many. If we take news as an example: if the time, effort and money that a news organisation puts into news gathering yields nothing, because RAG models will just copy-paste (albeit with attribution), I won’t be able to sustain this business.
Then who will AI steal from?
*
Read next: AI and the right to say no (Part 1 of this series on AI and Copyright)
I have a lot more to explain on AI and copyright. This is going to be a series of long reads. I would love comments, feedback and criticism, and even a detailed response that contradicts what I’m saying, especially if I can publish them with comments (or responses) in this newsletter. If you disagree with me on something, tell me and I’ll address that in future updates, even if you want to remain anonymous.
In terms of disclosures: I have a clear vested interest as a copyright owner, but I’m doing this purely on principle.
That’s the way I roll. Always have.
Any thoughts on decreasing the length of the copyright tenure?